Multilayer Perceptron Neural networks for Handwritten Character Recognition
Logan Greer, Eric Guidarelli, Joseph Mandara, Craig Szot, Ric Rey Vergara, and Ryan Wright

The primary objective of this project was to gain a basic understanding of machine learning by studying neural networks and applying MATLAB’s Neural Network Toolbox to perform character recognition on a widely studied dataset of hand-written characters. After evaluating the results of various features and network configurations with ten-fold cross-validation, an optimal network that combined distance profiles, projection histograms, and pixel features was selected. This network achieved a classification success of 88.12% ± 2.26% on all 62 characters, which is comparable to the reported successes of a convolution neural network and human classification.
Special Database 19 was acquired from the National Institute of Standards and Technology (NIST) for use in this project. This dataset contains 815,000 written characters (0-9, a-z, A-Z) acquired from 3,600 different writers for use in character recognition.

Sample Handwriting Form
One example of the form that was filled out to acquire the data now a part of SD 19. There were eight different forms sent out each with random groupings of numbers and letters, but all had the preamble from the US constitution at the bottom.

Original Image
Each physical form was scanned in and each character in a form was cropped to a 128x128 image with the character in the center. This was the form that all 815,000 characters were in at the start of this project.

Cropped Image
To reduce the total size of the database, every image was cropped to the edges of the character they contained and resized to 16x16 size to reduce the total size of the databass by 64 times. This process also discarded many pixels of the images that were the same across all characters, reducing similar pixels that would later be used as features.
Artificial Neural Networks are problem solving models inspired by biological neural networks (i.e. a brain). They consist of many interconnected nodes, akin to neurons, that receive and pass forward information, potentially through multiple layers. A node can receive multiple data inputs, and from them produce a single output. Multiple nodes can be created in a layer to receive different inputs and make different “decisions.” Creating additional layers of nodes allows outputs from the previous layer to be combined, which allows the network to view the data in more abstract ways.

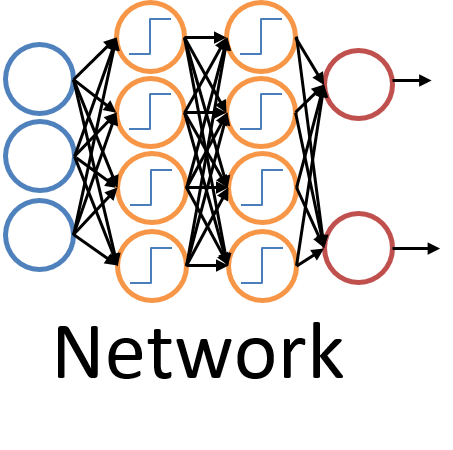
For this project, the network inputs were numerical features that describe the characters and help distinguish them from each other. The output targets were the 62 different character classes. Not shown here are two other features that were researched. Crossings and Euler Number features are explained in more detail in the report, but were not used in the final network and were therefore removed in this abbreviated format.
Pixels
This profile involves simply using the binary value of each pixel as a unique feature (white = 1, 0 = black).
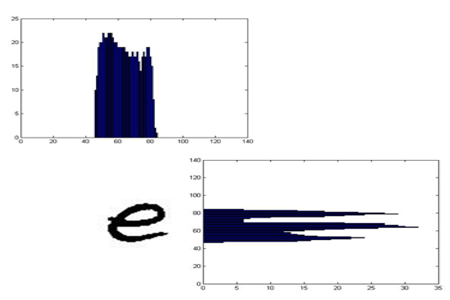
Projection Histogram
Projection histograms are generated by counting the number of pixels in each character row and column of a character image, and then projecting The number of black pixels in each area.
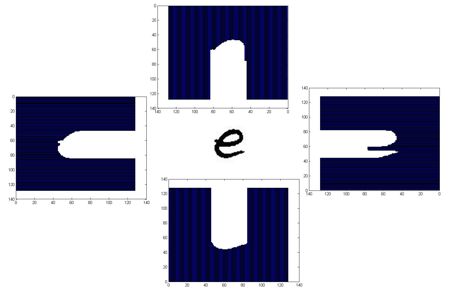
Distance Pofile
A distance profile counts the number of pixels (distance) from the bounding box of a character image to the outer edge of the character.
Principal Component Analysis (PCA) was performed on the features to locate the eigenvectors that contribute the most to the overall variance of the data. The transformed data was used as the new features space. Ten-fold cross validation was performed on each feature network.
| Feature | Network Configuration | Classification Success |
|---|---|---|
| Crossings | [150,110] | 36.59% ± 1.17% |
| Projection Histogram | [100] | 48.17% ± 0.74% |
| Distance Profile | [100,100] | 71.46% ± 1.47% |
| Pixel | [70,70] | 71.59% ± 14.49% |
| Merged | [90,90] | 81.94% ± 2.26% |
The optimal neural network utilized a combination of projection histograms, distance profiles, and individual pixels as features of interest. The success achieved by the merged network is comparable to the success of a convolution neural network committee (88.12% ± 0.09%), and the success of actual human classification (81.8% w/ 0.1% standard error).
Thanks for reading! If you enjoyed that or are looking for more check out the full report and poster by clicking on the red icon on the bottom right.